LocalOS - On-Device AI for Your Obsidian Vault
React Native app for on-device LLM inference - no cloud, no API keys. Chat with a local AI that reads, semantically searches, and writes your Obsidian vault. Three inference backends, on-device embeddings, voice input. Work in progress.
React Native app for on-device LLM inference - no cloud, no API keys. Chat with a local AI that reads, semantically searches, and writes your Obsidian vault. Three inference backends, on-device embeddings, voice input. Work in progress.
Project Overview
LocalOS is a React Native app for running large language models entirely on-device - no cloud, no API keys, no data leaving the phone. The core idea: "chat with a local AI that can read, search, and write your Obsidian vault." Notes are chunked, embedded, and semantically searched locally, so the assistant can reason over a personal knowledge base without any of it touching a server.
The app supports three inference backends: llama.cpp (via llama.rn) for fully local models, Apple Intelligence on the Neural Engine for iOS 18+ devices, and LM Studio for offloading to a desktop on the same network. It runs two models simultaneously - a chat model and an embedding model - to power retrieval-augmented answers over the vault. Tool calling with multi-step orchestration enables search-fetch-synthesize workflows, and Whisper-based voice input allows speech-to-text on-device. GPU acceleration uses Metal on iOS and OpenCL on Android, with conversation history persisted in SQLite (FTS5 + vector search).
Default models reflect the on-device constraints: Llama 3.1 8B Instruct (Q4_K_M, ~4.9 GB) for chat, Nomic Embed Text v1.5 (Q8_0, ~130 MB) for embeddings, and Whisper base (~147 MB) for speech. Targets iOS 14+ (18+ for Apple Intelligence) and Android devices with 6 GB+ RAM.
**Status:** Work in progress. The architecture is in place (modular services for AI, vault, database, and session management) and the core inference + vault search flow works, but the app is under active development and not yet released.
Key Features
- •On-device LLM inference - no cloud, no API keys, no data leaves the device
- •Three inference backends: llama.cpp, Apple Intelligence (Neural Engine), and LM Studio
- •Obsidian vault integration - chunk, embed, and semantically search markdown notes locally
- •Dual-model architecture running chat and embedding models simultaneously
- •Tool calling with multi-step orchestration (search-fetch-synthesize)
- •Whisper-based voice input for on-device speech-to-text
- •GPU acceleration via Metal (iOS) and OpenCL (Android)
- •SQLite-backed persistence with FTS5 and vector search
Project Gallery
Technical Challenges & Solutions
Challenge 1
Running both a chat model and an embedding model on memory-constrained mobile hardware
Solution
Designed a dual-model architecture where a quantized chat model (Llama 3.1 8B, Q4_K_M ~4.9 GB) and a small embedding model (Nomic Embed v1.5, Q8_0 ~130 MB) run together. Used aggressive quantization and GPU acceleration (Metal on iOS, OpenCL on Android) to keep inference usable, and gated Apple Intelligence/Neural Engine paths to capable devices (iOS 18+, 6 GB+ RAM on Android).
Challenge 2
Semantic search over an Obsidian vault entirely on-device
Solution
Built a pipeline that chunks markdown notes, generates embeddings locally, and stores them in SQLite with FTS5 plus vector search - no external vector DB or API. Retrieved chunks feed the chat model for retrieval-augmented answers, keeping all vault data on the device.
Results & Impact
Fully on-device AI assistant with zero cloud dependency
Local semantic search over a personal Obsidian knowledge base
Experience integrating multiple inference backends (llama.cpp, Apple Intelligence, LM Studio)
Hands-on work with on-device embeddings, vector search, and mobile GPU acceleration
Technologies Used
Project Links
Interested in this project?
Let's discuss how I can help with your similar requirements.
Get in TouchSimilar Projects
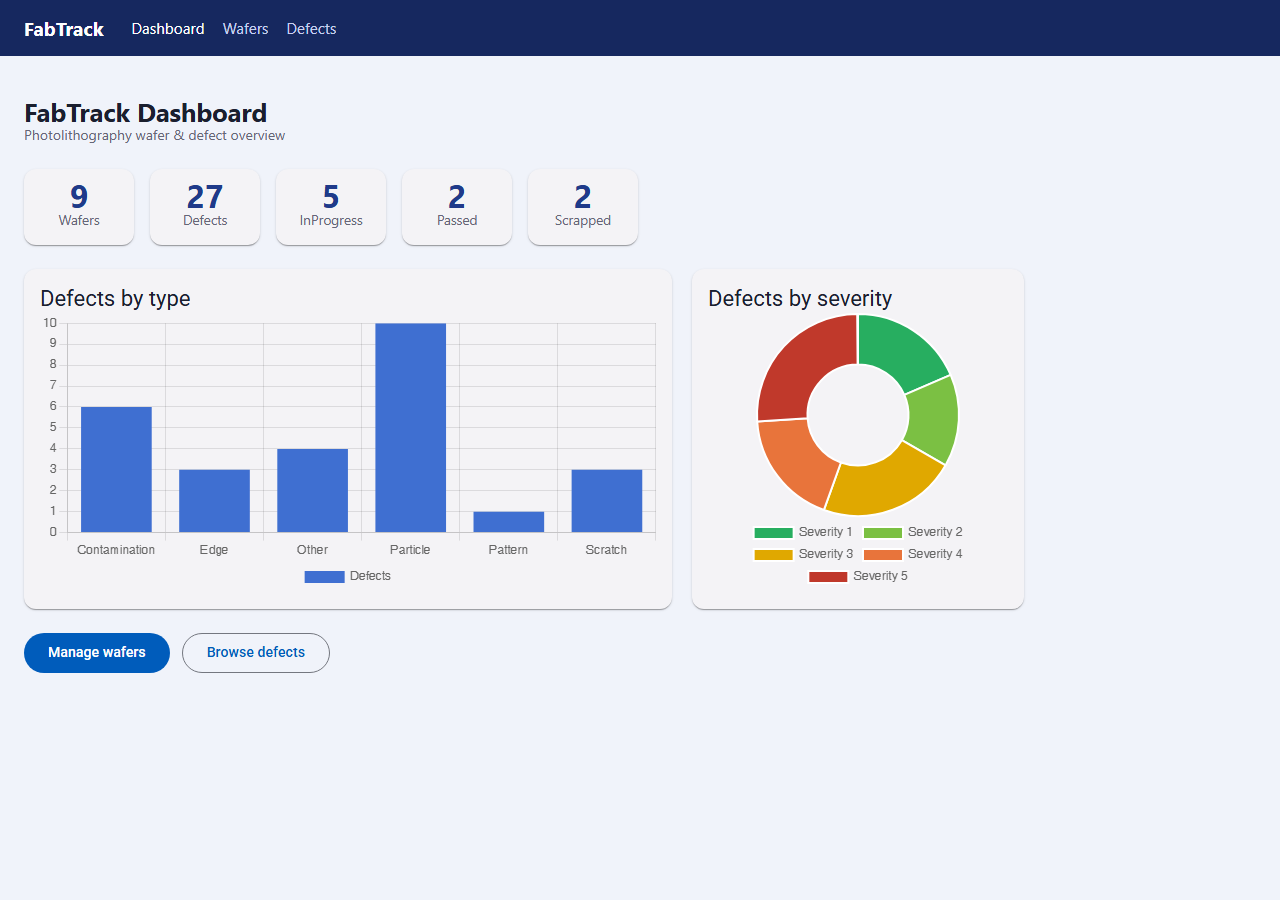
FabTrack - Wafer Defect Tracker
Full-stack .NET + Angular app for tracking silicon-wafer defects. Plots defects on the wafer surface by location and severity, with a charted dashboard. Built to demonstrate ASP.NET Core + Angular.

AutoPartsDB - Inventory Management System
Inventory management system that transformed a monolithic Excel file with 900+ columns into a relational database. Features relationship visualization for parts-suppliers-clients, work table sync functionality, and automatic backups.
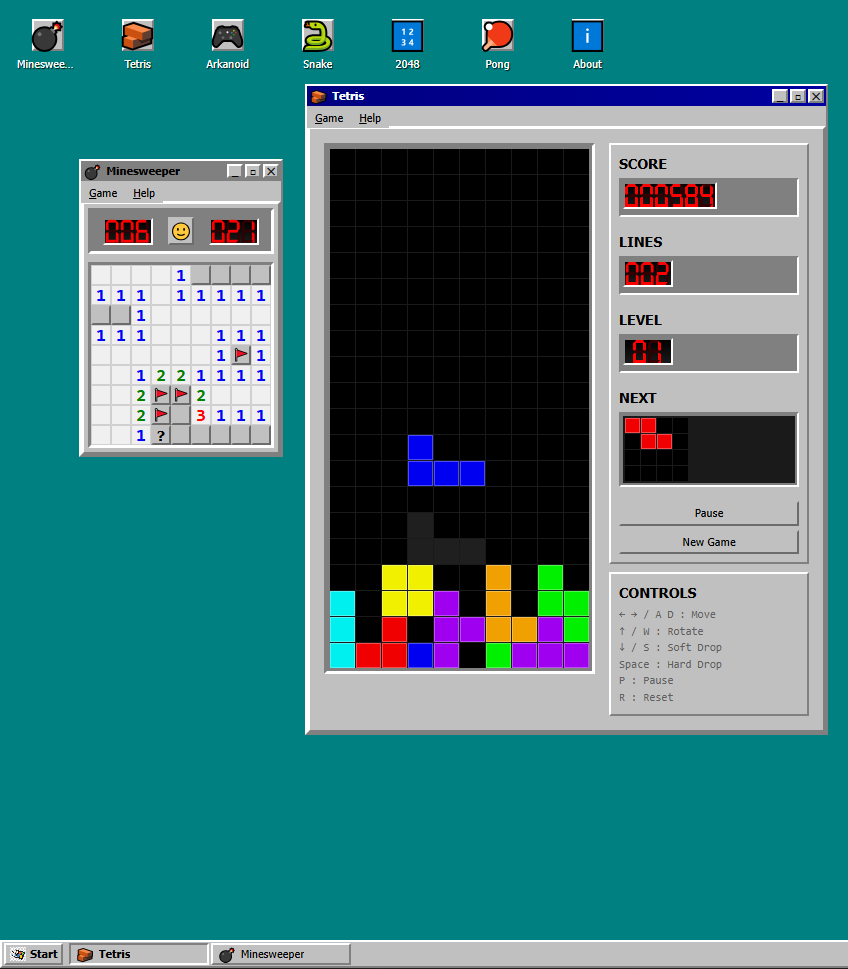
Win95Games - Retro Gaming Platform
Collection of 6 classic Windows 95 games with authentic retro desktop experience. Features Minesweeper, Tetris, Arkanoid, Snake, 2048, and Pong in a pixel-perfect Windows 95 UI with window management and smooth animations.